GLM 5.1 Inference Benchmark
By Lucas Ewing
TL;DR
We serve GLM 5.1 at $0.90/M input, $3.00/M output on shared warm endpoints running on idle enterprise GPUs. In our current benchmark snapshot, Lilac lands at the lowest per-token price among GLM 5.1 providers in the comparable-speed band. Get API access or email contact@getlilac.com.
About GLM 5.1
GLM 5.1 is Zhipu AI's latest open frontier model. It's strong on coding, reasoning, and long-context tasks, and it's fully supported on Lilac's shared endpoints today.
| Model | Input Price | Output Price | Latency |
|---|---|---|---|
| GLM 5.1 | $0.90 / M tokens | $3.00 / M tokens | 0.58s TTFT |
The API is OpenAI-compatible. Switching takes one line:
from openai import OpenAI
client = OpenAI(
base_url="https://api.getlilac.com/v1",
api_key="lilac_sk_...",
)
response = client.chat.completions.create(
model="zai-org/glm-5.1",
messages=[{"role": "user", "content": "Hello!"}],
)
How we compare
We benchmarked our endpoint with NVIDIA AIPerf at 100 concurrent requests and compared against every GLM 5.1 provider listed on OpenRouter.
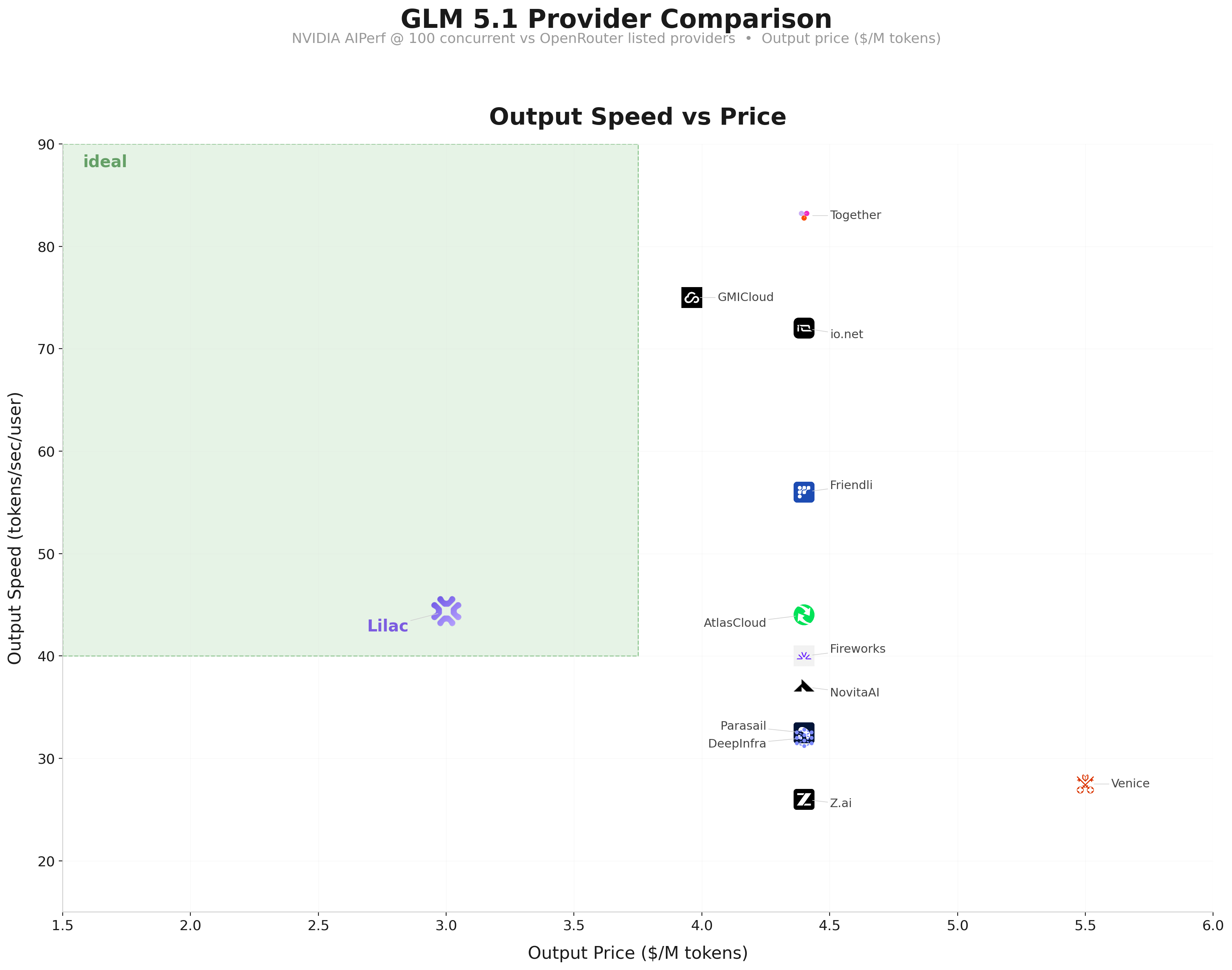
At 44 tokens/sec per user with 0.58s TTFT and $3.00/M output, Lilac is the only provider in this comparison under $4/M output. Together and GMICloud push higher throughput (83 and 75 tps respectively), but at $4.40 and $3.96/M output.
Why we can price GLM 5.1 this way
The average enterprise GPU cluster runs at about 50% utilization. Training jobs finish, inference traffic dips, and the hardware just sits there. The power, cooling, and depreciation are already paid for.
Lilac's Kubernetes operator finds that spare capacity and spins up GLM 5.1 inference workloads on it. When the cluster's own jobs need GPUs back, our operator steps aside immediately. The GPU owner's workloads always come first.
Since the fixed costs are already covered, the cost of serving inference on that spare capacity is much lower than renting dedicated GPUs. We pass those savings through to you.
How the operator works
GPU providers install our Kubernetes operator with a single kubectl apply. It does four things:
- Monitors node utilization and finds reclaimable GPU capacity
- Deploys inference servers (vLLM) onto idle nodes
- Routes API requests to healthy instances
- Preempts inference workloads when primary jobs need GPUs back
Providers choose which node pools to expose and set their own availability windows. Their workloads always take priority.
Related reading: How Idle GPUs Make Cheap Inference Possible (our Kimi benchmark), GPU Inference API Pricing Compared, and the inference section.